4. Deep Neural Network
시작에 앞 서…
이 글은 Coursera의 Neural Networks and Deep Learning Deep 수업을 정리한 자료입니다.
교수님의 말씀을 잘 이해하지 못한 부분도 있으니, 수업을 들으시면 더욱 좋을 것 같습니다.
- Week1 : Introduction Deep Learning
- Week2 : Neural Networks Basics
- Week3 : Shallow Neural Network
- Week4 : Deep Neural Network
Deep L-layer neural network
지금까지, logistic regression 과 hidden layer가 하나인 2-layer neural network를 살펴 보았습니다. 여러 hidden layer를 가지는 neural network 살펴볼 차례입니다. 각 layer를 효과적으로 표현하기 위해서, 몇 가지 notation(표기법)을 살펴 보겠습니다.
- : 전체 layer의 수(input layer는 제외)
- : 번째 layer의 neuron의 수
- : 번째 layer의 activation 값들,( )
여기서 기억하셔야할 점은, layer는 superscripts(윗 첨자)로 표시되고 으로 표시되고 있다는 점입니다.
Forward Propagation in a Deep Network
지난 주에 진행한, Forward Propagation와 다를게 없습니다. 동일하게 와 을 구하면 되겠습니다. 앞 서 표기와 다르게, Capital character(대문자)는 matrix의 모든 행과 열 뜻합니다. 여기서 행은 feature나 neuron과 관계되며, 열은 data 하나 하나의 case를 의미하겠습니다. 그렇기 때문에, 한 번에 여러 hidden layer 표현할 수 없습니다. 명시적인 for-loop를 통해서 각 layer를 순회하는 구조로 프로그램을 작성하게 됩니다. matrix의 차원을 늘려서 처리하는 방법을 생각할 수도 있겠지만, 이전 layer가 다음 layer에 영향을 미치므로 vectorization이 적용되기 어렵습니다.
Getting your matrix dimensions right
neural network을 작성하실 때, 꼭 신경쓰셔야 하는 부분이 바로 각 parameter의 차원의 크기 입니다. 이것만 잘 기억하고 계셔도, 알고리즘의 작성이나 debugging시에 도움을 받을 수 있습니다.
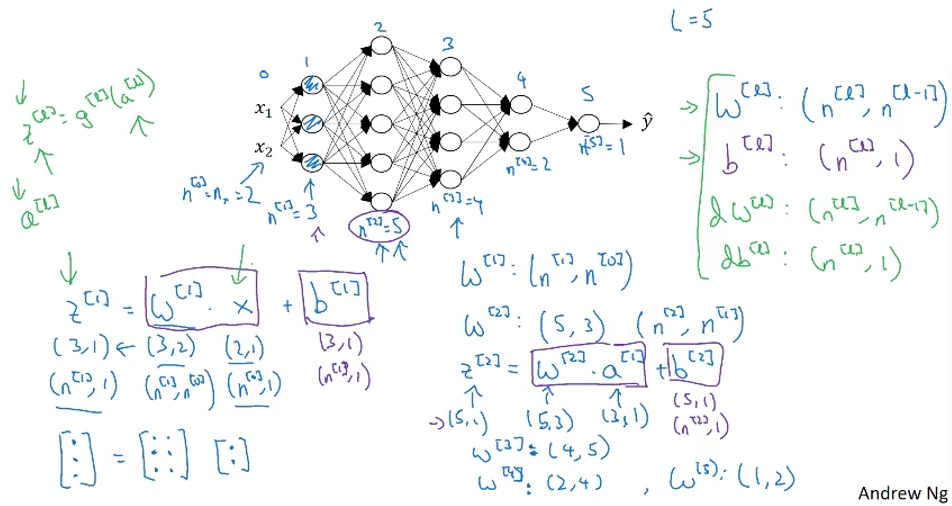
엄청 복잡하죠? 하지만, 자세히 들여다 보면 몇몇 수에 의해서 구성되고 있음을 알 수 있습니다. 그 숫자들만 기억하면 나머지는 충분히 유추되어질 수 있는 수들입니다. 그 기준이 되는 수는 ‘ 번째 layer 안에 neuron의 수’를 뜻하는 입니다. 이 수를 기준으로 와 는 결정됩니다. 아래와 같은 식이 있다고 했을 때,
그 각각의 shape(크기)는 다음과 같습니다.
앞에서 말씀드린 것처럼, 에 의해서, 각 shape이 결정되고 있음을 알 수 있습니다.. shape에서 의 의미는 하나의 data sample을 의미합니다. 전체 data에 대해서는 vectorization을 한다면, 1이 (전체 data의 수)으로 변경해서 적용하면 되겠습니다. 지금까지 forward propagation이었고, 이 부분은 상당히 직관적이라 큰 어려움이 없습니다. 그에 반해, back propagation은 각 값들이 어렵게만 느껴지고, 구해도 맞는건지 확신이 서지 않을 때가 있습니다. 그렇기에, 아래의 내용은 꼭 기억해 두시는게 좋을 것 같습니다.
- :
- : 으로 과 같은 크기
- : 으로 과 같은 크기
위의 (1)과 비교해 보면, 미분과 상관없이 동일한 크기를 가짐을 알 수 있습니다.
Why deep representations?
hidden layer가 하는 일은 도대체 뭘까요? 왜 hidden layer를 추가하면 더욱 좋은 성능이 나타나는 것일까요? 이번에는 hidden layer가 어떤 역활을 하는지 살펴보겠습니다. 사람의 얼굴을 인식하는 3개의 hidden layer로 구성된 face detection system을 생각해 보겠습니다. 첫 번째 hidden layer는 edge들을 추출하고 2번째 layer에서는 얼굴의 부위를 구성합니다. 마지막 layer에서는 얼굴의 부위를 조합하여 얼굴을 완성합니다. 그렇게 만들어진 얼굴을 우리가 찾는 얼굴인지 output layer에서 최종적인 판단을 하고 그 결과를 반환하게 됩니다. 물론, 실제적으로 각 layer가 그런 식으로 나눠지거나 명확하게 분리되는 것은 아닙니다. 다만, 여기서 기억해야 할 점은, hidden layer는 이전 layer들을 종합 구성하는 역활을 한다는 사실입니다. data가 hidden layer를 통과할 수록, 더 집적적이고 유의미한 정보를 뽑아낼 가능성이 높아진다는 점입니다. 음성 인식도 마찬가지 입니다. 소리 레벨에서 음절 단위로, 그 다음에는 단어 단위로 구성해가며 최종 결과를 찾아가는 구조라는 점입니다. 만약, 여러 hidden layer를 단일 hidden layer로 구성하는(shallow NN) 경우에, 필요한 neuron은 2^(n-1)에 해당한다고 합니다.
Building blocks of deep neural networks
각각의 hidden layer를 하나의 block으로 생각하면, 조금 더 이해하기 쉽습니다.
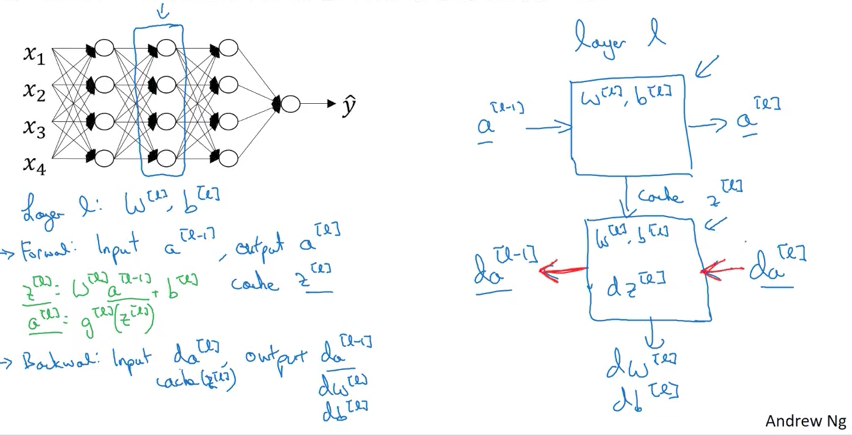
layer l이 있다고 할 때
인 점을 기억하시고, 이제 실질적인 구현을 살펴 보겠습니다.
Forward and Backward Propagation
Forward propagation의 경우, , 그리고 을 이용해서 구해가면 됩니다.
하지만, Backward Propagation은 그 보다 훨씬 복잡하고 어렵습니다.
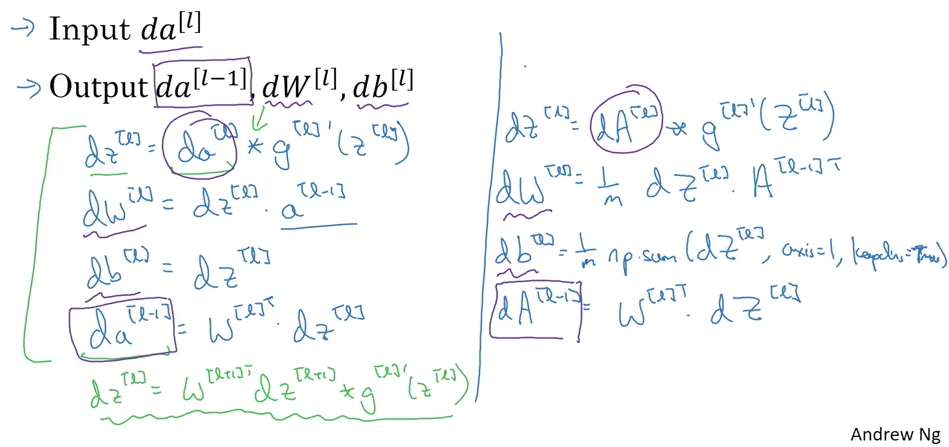
이전 시간까지 계속 보아왔던 내용이지만, 여전히 새롭습니다. 위에서 정의한 것처럼, 구하는게 핵심입니다.
위의 수식이 하나의 layer에 대해서 정리된 것이므로, 이러한 작업을 각 layer마다 진행해 주어야 합니다.
Parameters vs Hyperparameters
지금까지 parameters인 w, b를 보아 왔습니다. Hyperparameters에 대해서 살펴 볼텐데, algorithm design과 관련된 parameter가 되겠습니다.
- learning rate A
-
of iteration
-
of hidden layers
-
of hidden unit for each layer
- activation function
이번 강의에서는 배우지 않았지만,
- momentum
- mini batch size
- regularization parameters
들도 포함된다고 합니다. 이러한 parameter에 대해 최적의 값은 없습니다. 데이타나 모델, 환경에 따라 달라질 수 있으며, 최적의 값을 찾기 위해서는 여러 시행을 할 수 밖에 없다고 합니다. empirical process(경험적 절차)라고 표현하셨는데, 앞으로 많은 연구와 개발이 필요한 이유이기도 합니다.
What does this have to do with the brain?
neuron이라고 NN에서 사용하고 있지만, 아직 뇌 과학자들도 정확히 neuron의 역활에 대해서 아직 알지 못한다고 합니다. 교수님의 생각에는 아직 빈약한 유추(loose analogy)로 생각된다고 하시네요.